It’s now been five years since the HMDA reporting requirements were dramatically expanded in 2018, and, in my assessment, there continue to be substantial data quality concerns. In this blog, I will focus specifically on one field, the debt-to-income (DTI) ratio, which seems to be a source of perpetual headaches for reporting institutions.
What are the repercussions of bad DTI data in HMDA analysis?
If you are a larger institution, you’ll probably conduct logistic regression modeling in your underwriting analysis, and the DTI ratio will likely be entered as a model control. The adage is “garbage in, garbage out”. If the DTI data are not appropriately computed or do not represent the ratios the underwriters relied on when deciding on an application, the model results will be unreliable.
Another concern is that there will be hundreds of denials (if not thousands) for which DTI is reported as “NA.” Usually, categorizing the variable rather than entering it as a continuous variable would be the way to handle missing data, but if the only NA values are denials, then the only option may be to exclude these records from your model, which could bias your results.
Now, suppose you’re a smaller institution that only conducts match pairs but does not have enough records for regression modeling. If your DTI field includes some “NA” values that were entered as a mistake, you may turn up zero match pairs when otherwise you would have matches that would warrant scrutiny.
Are financial institution examiners noticing DTI issues?
In the summer of 2021, the CFPB Supervisory Highlights documented several HMDA data quality concerns, including DTI:
Examiners identified widespread errors within the 2018 HMDA LARs of several covered financial institutions. In several examinations, examiners identified errors that exceeded the HMDA resubmission thresholds. In general, examiners identified more errors in data fields collected beginning in 2018, according to the 2015 HMDA rule, than for other fields. For example, the fields with the highest number of identified errors across several institutions were the newly required “Initially Payable to Your Institution” field and the [DTI] field.
In the same document, the CFPB went on to describe the threshold for resubmission:
The HMDA interagency resubmission thresholds provide that in a LAR of more than 500 entries, when the total number of errors in any data field exceeds four, examiners should direct the institution to correct any such data field in the full HMDA LAR and resubmit its HMDA LARs with the updated field(s).
What does a healthy process look like for getting the HMDA data right?
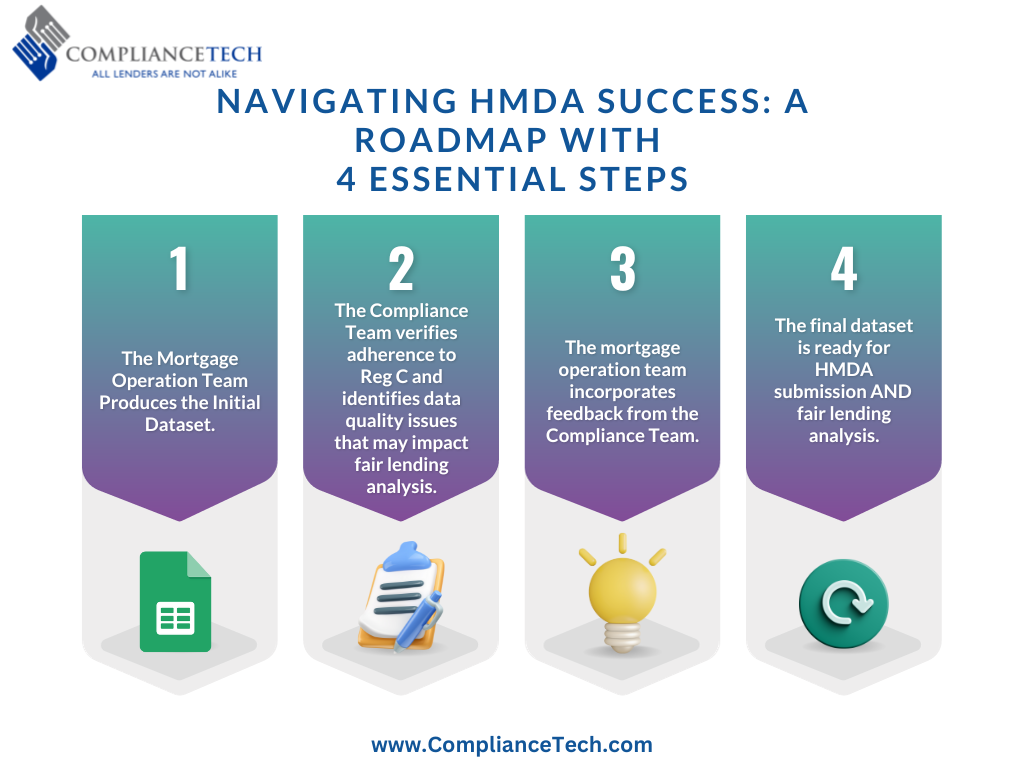
My suggestion would be to follow the process below:
- Mortgage Operation Team Produces the Initial Dataset
- Compliance Team ensures compliance with Reg C and uncovers data quality issues that could affect fair lending analysis
- The mortgage operation team incorporates feedback from the compliance team
- Final dataset, ready for HMDA submission as well as fair lending analysis
Where you have “NA” values among denials, particularly those where the debt ratio was cited as the reason for denial, I would seek to understand why the “NA” reporting was used. There may be a completely reasonable explanation for it.
I recommend you take a look at the share of applications coded as “NA,” both across all decisioned applications and within denials specifically. Especially if that share exceeds 30%, proceeding with analysis without first asking “Why?” should be considered a “rookie mistake.” It can be hard to resist the temptation to dive immediately into analysis, but sometimes a pause is necessary.
How can ComplianceTech help?
ComplianceTech’s Suite of Products™ can help your compliance team assess data quality for Reg C compliance and fair lending analysis. Specifically, HMDA Ready™ and Fair Lending Magic™ are the two tools where mortgage data can be scrutinized. Contact us today for a personalized demonstration.